Visual Variation Learning for Object Recognition
- We propose visual variation learning to improve object recognition with convolutional neural networks (CNN). While a typical CNN regards visual variations as nuisances and marginalizes them from the data, we speculate that some variations are informative.
- We study the impact of visual variation as an auxiliary task, during training only, on classification and similarity embedding problems.
- Our key contribution is that, at the cost of visual variation annotation during training only, CNN enhanced with visual variation learning learns better object representations.

Gradient-weighted class activation mapping (Grad-CAM) on iLab-2M test data. Both object instances are misclassified as car on ResNet without variation learning and correctly classified as van and monster on ResNet with variation learning (ResNet+Pose). The heatmaps on the second row highlight regions of the image that activate the incorrect class on ResNet and on the third row hightligh regions that activates the correct class on ResNet+Pose. ResNet+Pose is more tuned to the shape of an object across poses and focuses on distinctive features of each category (flat front of the van and oversized wheels of the monster truck).
[DOI: 10.1016/j.imavis.2020.103912][Preprint]
Data
iLab-20M
The iLab-20M dataset is a large-scale controlled, parametric dataset of toy vehicle objects under variations of viewpoint, lighting, and background. The dataset is produced by placing a physical object on a turntable and using multiple cameras located on a semicircular arc over the table.
- 15 categories: boat, bus, car, equipment, f1car, helicopter, military, monster truck, pickup truck, plane, semi truck, tank, train, UFO, and van
- 718 object instances
- 88 different viewpoints (11 elevations x 8 azimuths)
- 5 lighting conditions
- 3 camera focus settings
- 14–40 background images
- 22 million images total

The iLab dataset provides toy vehicle images from 15 categories in various viewpoints, lighting conditions, and backgrounds.
[DOI: 10.1109/CVPR.2016.244] [Open Access]
iLab-80M
The iLab-80M is an augmented set of the iLab-20M adding random crops and scales. The augmentation ensures that the number of images per category is well balanced, resulting in 5.5 million images per category and a total of 82.7 million images for the whole set.
In addition, the original 960x720 images are cropped around each object and rescaled to 256x256.
iLab-2M
The iLab-2M is a subset of iLab-80M sampled for experiments conducted in this work. In iLab-2M, data vary only in pose variation, while other visual variations are kept constant.
- 30 poses (5 elevations x 6 azimuths)
- 1.2M training images, 270K validation images, 270K test images

iLab-2M-Light
The iLab-2M-Light is an extension of the iLab-2M that includes lighting conditions as an additional visual variation.
- 30 poses (same as iLab-2M)
- 5 lighting conditions
- 1.36M training images, 316K validation images, 316K test images
Methods
1. Variation Classification
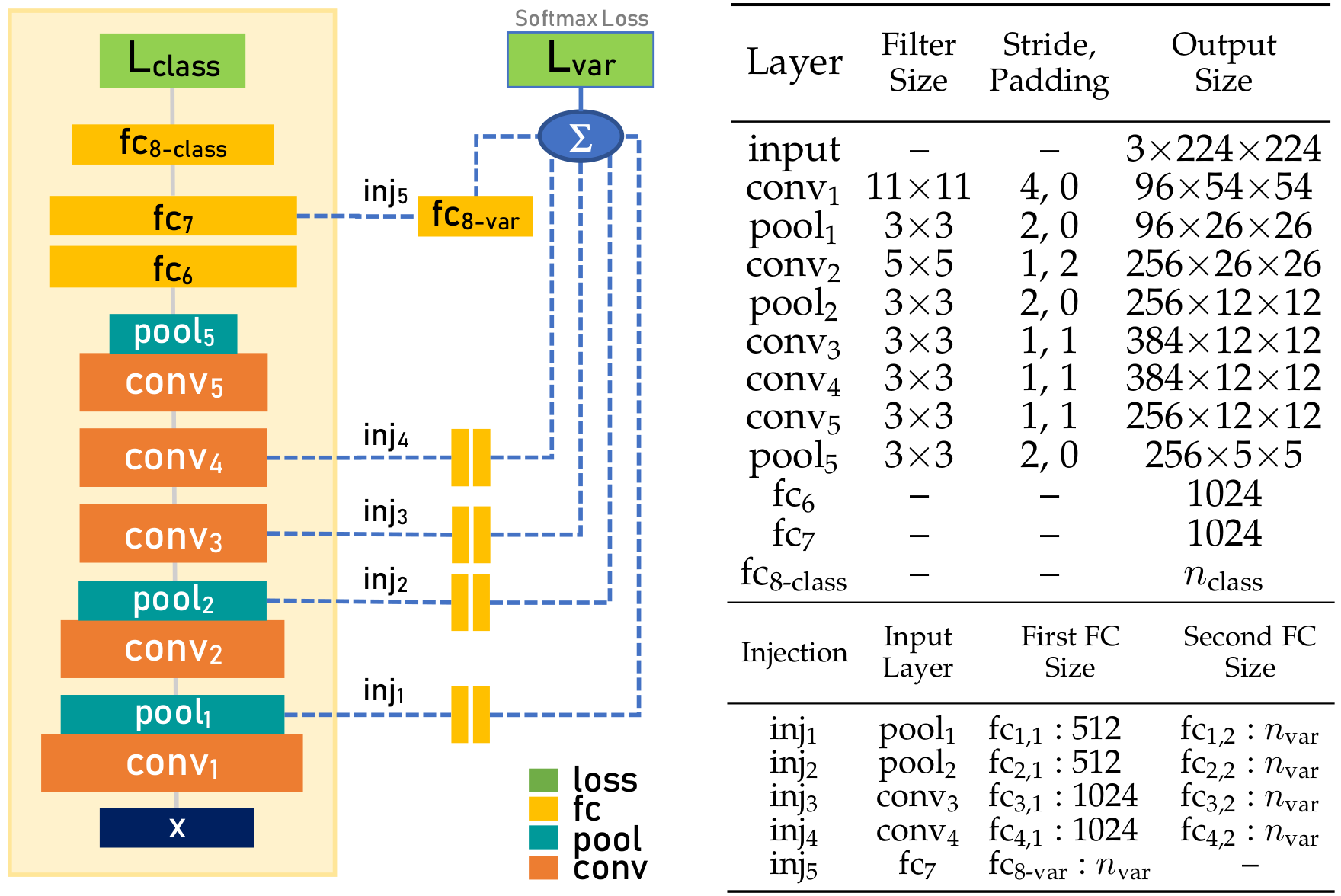
A multi-layer variation-injected CNN built on top of AlexNet. AlexNet is enclosed inside the left box. All additional components on the right are part of the variation classification module. Dotted lines represent injection connections that connect intermediate conv/pool layers to transformation (fc) units. Outputs of transformation units are summed into variation scores.
2. Variation Embedding Learning
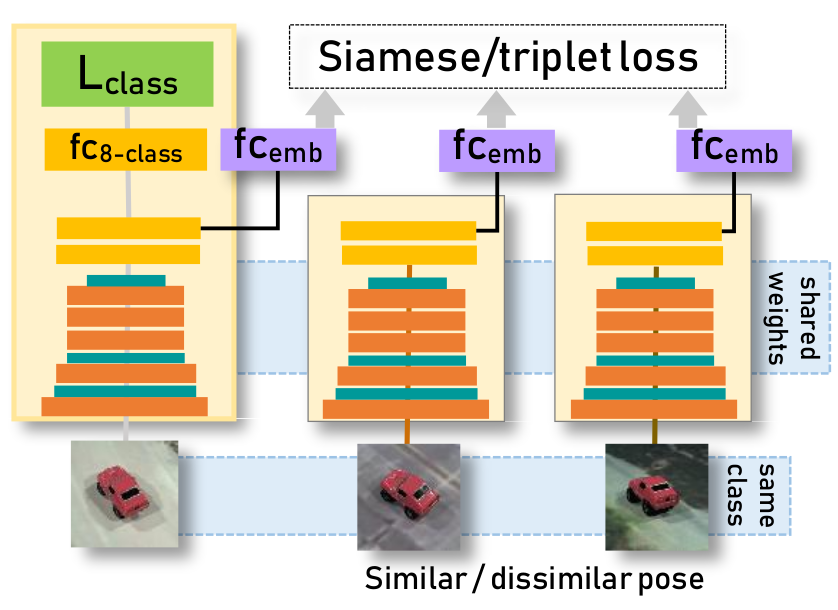
A conceptual diagram of an embedding network. The main AlexNet network takes an anchor input and produces class probability scores. For Siamese setting, the second network in the middle takes a second input of the same object instance but with either similar or dissimilar pose. For triplet setting, the second and the third network takes one similar pose and one dissimilar pose. Both auxiliary networks output an embedding vector representing a point in pose embedding space.